Snelheid van XML input verhogen met Common variabelen
De snelheid waarmee Datastage XML bestanden verwerkt laat wat te wensen over. dat komt voornamelijk omdat de XML input stage het hele bestand in het geheugen laadt en het dan gaat verwerken. Zo duurde het verwerken van een datastage export van 75 MB wel 25 minuten op de server die ik tot mijn beschikking had. Omdat dit niet echt snel is, had ik het idee om het bestand zelf op te delen in kleinere stukken en die dan per stuk aan te bieden aan de XML input stage. In dit geval besloot ik de Datastage export op te delen in Jobs door het originele bestand regel voor regel in te lezen en dan de stukken van <Job...> tot en met </Job...> aan te bieden aan de XML input stage.
De meest voor de hand liggende manier om dit te doen is alle regels aan elkaar te plakken in een stage variabele en dan bij de laatste regel van een sectie, alle regels naar de XML input stage te sturen. Het werkte maar de snelheid was nog niet om over naar huis te schrijven. Uit testen bleek dat het niet aan de XML input stage lag want als ik het resultaat naar een tekstbestand schreef, was de job nog steeds langzaam. Blijkbaar zorgt het opbouwen van een enorme string in een stage variabele voor vertraging.
De andere oplossing om alle regels aan elkaar te koppelen is Common variabelen (tip van Tim Renicar). Om de data op te slaan in een Common variabele, heb ik de volgende twee functies gemaakt:
Function SetCommonVar(str, varno, init)
Common /Stringcollect/ data1, data2, data3
Begin Case
Case varno = 1
If init = 'Y'
then data1 = str
else data1 = data1 : str
Case varno = 2
If init = 'Y'
then data2 = str
else data2 = data2 : str
Case varno = 3
If init = 'Y'
then data3 = str
else data3 = data3 : str
End caseFunction GetCommonVar(varno)
Common /Stringcollect/ data1, data2, data3
Ans = ""
Begin Case
Case varno = 1
Ans = data1
data1 = ""
Case varno = 2
Ans = data2
data2 = ""
Case varno = 3
Ans = data3
data3 = ""
End caseLees job parameters job
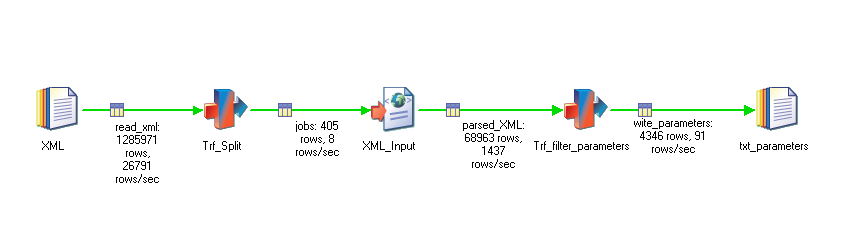 Met de functies heb ik de volgende job gemaakt. Het leest een datastage export XML en schrijft alle jobparameters met hun default waarde naar een tekstbestand. Aan de statistics is te zien dat het originele bestand 1285971 regels heeft (link 1) en dat er 405 jobs in zitten (link 2). Na het parsen komen er 68963 subrecords uit (link 3) waarvan 4346 parameters (link 4).
Met de functies heb ik de volgende job gemaakt. Het leest een datastage export XML en schrijft alle jobparameters met hun default waarde naar een tekstbestand. Aan de statistics is te zien dat het originele bestand 1285971 regels heeft (link 1) en dat er 405 jobs in zitten (link 2). Na het parsen komen er 68963 subrecords uit (link 3) waarvan 4346 parameters (link 4).
Trf_split
 In de transformer Trf_split worden de regels samengevoegd en gebundeld per job. Bij elke wordt de regel naar de jobs link gestuurd.
In de transformer Trf_split worden de regels samengevoegd en gebundeld per job. Bij elke wordt de regel naar de jobs link gestuurd.
XML input stage
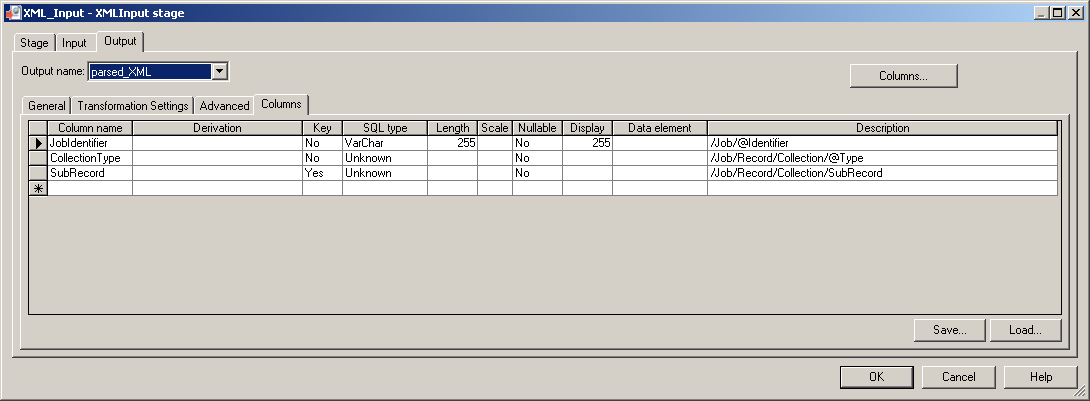 Aan de output tab van de XML input stage is te zien dat de xpath query uitgaat van Job op het laagste niveau.
Aan de output tab van de XML input stage is te zien dat de xpath query uitgaat van Job op het laagste niveau.
Trf_Filter_parameters
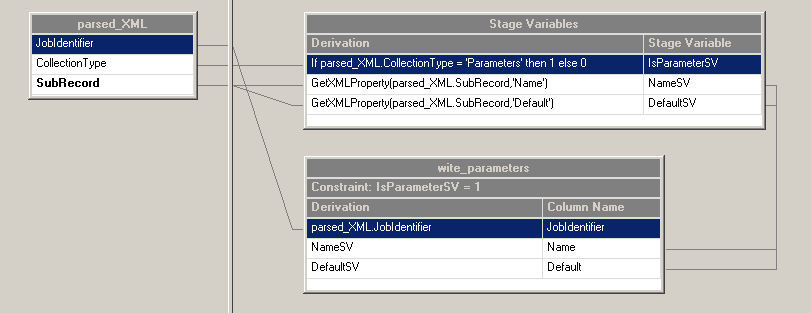 In deze transformer stage worden alleen de subrecords van parameters doorgelaten.
In deze transformer stage worden alleen de subrecords van parameters doorgelaten.
Resultaat
Het snelheidsverschil is enorm. Waar de job er eerst 25 minuten over deed, doet deze job het in 32 seconden. Dat is bijna 50 keer zo snel.