Remove duplicates retaining first/minimum row in Datastage
 There are two solutions in Datastage to remove duplicates and retain the first row of the set.
There are two solutions in Datastage to remove duplicates and retain the first row of the set.
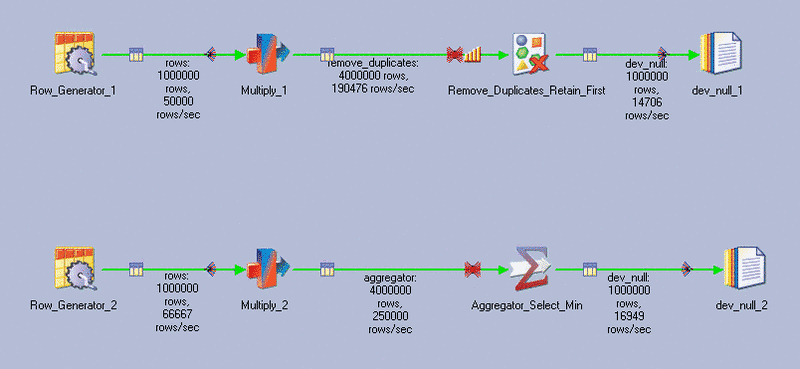
Use the remove duplicates stage and use link partitioning and sorting to make sure the correct row is retained Use the aggregator and select minimum values I was curious if there was any performance difference between the two options so i created this test job.
The job gerenates 1,000,000 rows and multiplies that by four in the transformer stage with a while loop construction. This creates four duplicate rows with minor differences. These rows are then dedupliced using the remove duplicates and aggegator stage. The result is written to /dev/null to minimize the impact of I/O.
The streams are not 100% equal. The aggregator stage takes the minimum value of both the non-key fields and the remove duplicates stage selects the row with the lowest sequence number. In this case the outcome is the same but it may be different in your job.
Multiply rows with loop condition
![]() The while loop generates four rows for each input row. It creates a 'business key' composed by the row number concatenated to a string to create a NVarChar key.
The while loop generates four rows for each input row. It creates a 'business key' composed by the row number concatenated to a string to create a NVarChar key.
It also adds the loop variable to the output and a timestamp with the loop variable added.
Set key for remove duplicates stage
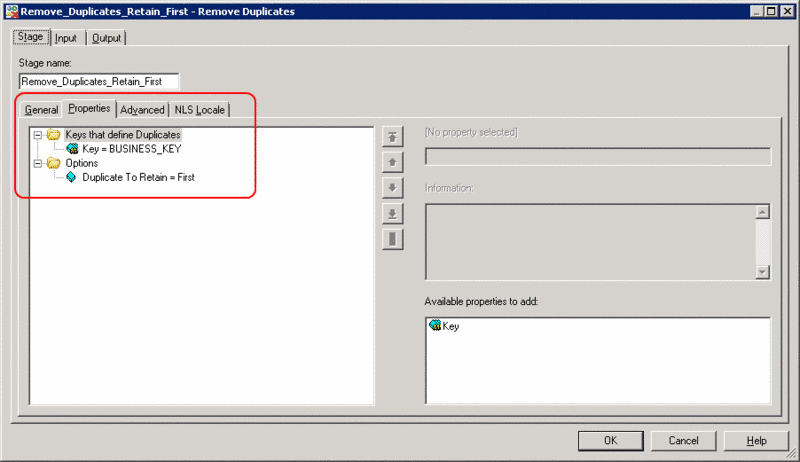 The 'business key' is set as key in the remove duplicates stage.
The 'business key' is set as key in the remove duplicates stage.
Partition input link in remove duplicates stage
 The trick of getting the first row in from the source is to sort the input row with partitioning. The data is sorted and partitioned on business key and sorted on the seq. Note that the seq is only sorted and not used for partitioning.
The trick of getting the first row in from the source is to sort the input row with partitioning. The data is sorted and partitioned on business key and sorted on the seq. Note that the seq is only sorted and not used for partitioning.
Set aggregator properties
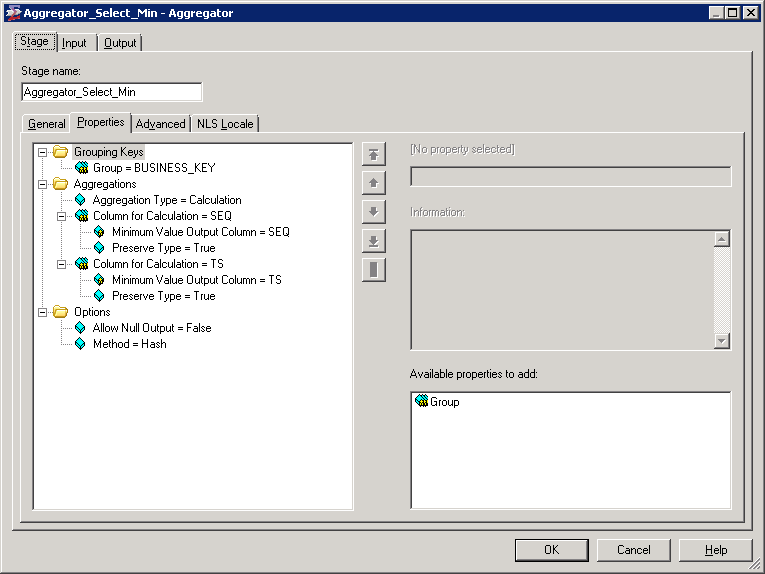 The aggregator is configured to group on the business key and select the minimum value of the seq and ts fields.
The aggregator is configured to group on the business key and select the minimum value of the seq and ts fields.
Is there a performance difference between remove duplicates stage and aggegator stage?
I've ran this job multiple times and the outcome differs each time i ran it. Both streams are equally fast. Sometimes the remove duplicates stage is faster and sometimes the aggregator is faster. You can choose the one that suits your needs.