Lookup File Sets: the hashed files for parallel jobs
I used hashed files a lot in Datastage server edition and noticed that you couldn't use them in parallel jobs. Luckily there's an alternative that offers some of the functionality from hashed files.
Here are some quirks in using them
Joins are implicit
When you try to drag the key column to the lookup link you'll get the following error:
Key expression cannot be set to an individual column for Lookup file set reference. Check range checkbox and then edit the expression by double clicking on expression box or use the contect menu.
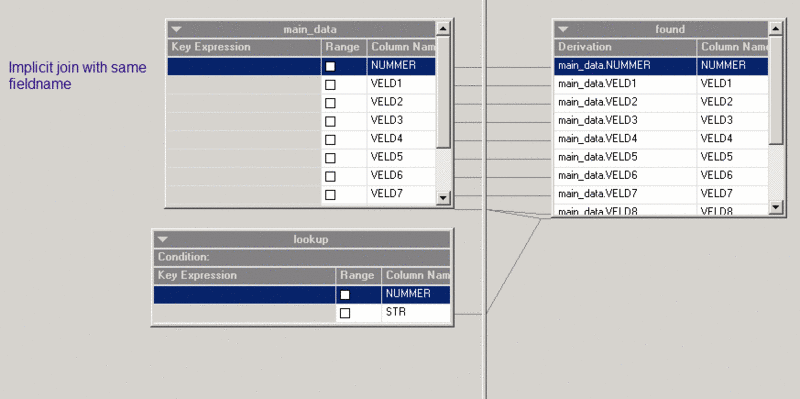 The difference with a 'normal' lookup is that you don't have to connect the key columns. You'll just have to make sure that the main stream lookup column has the same name as the key in the Lookup File Set. If the main stream doesn't have the same name, you'll get the following error on running the job:
The difference with a 'normal' lookup is that you don't have to connect the key columns. You'll just have to make sure that the main stream lookup column has the same name as the key in the Lookup File Set. If the main stream doesn't have the same name, you'll get the following error on running the job:
Lookup,0: Could not find input field "NUMMER".
In the example on the right, both links contain the 'NUMMER' column so thats used for the lookup.
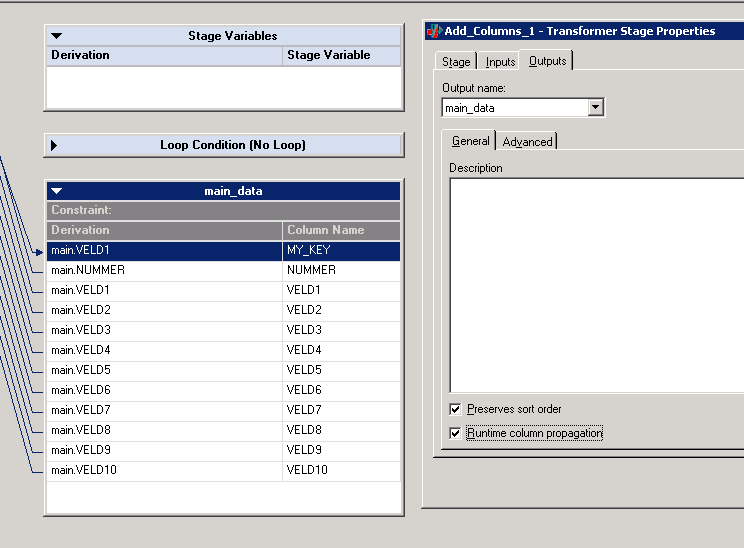 Implicit joins can be confusing but it's not all bad. One advantage from implicit joins is that you can use column propagation on the main stream and the lookup will still work.
Implicit joins can be confusing but it's not all bad. One advantage from implicit joins is that you can use column propagation on the main stream and the lookup will still work.
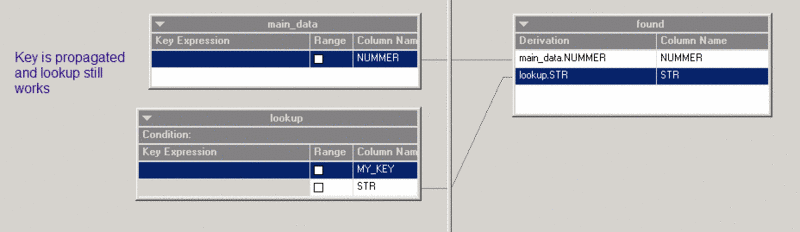 The column 'MY_KEY' is propagated and is not visible in the lookup stage but the lookup still works without a problem.
The column 'MY_KEY' is propagated and is not visible in the lookup stage but the lookup still works without a problem.
You cannot create a Lookup File Set and read from it in the same job
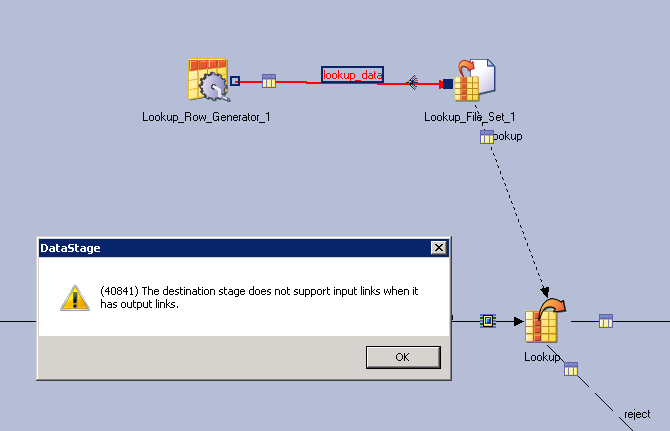 You cannot create a Lookup File Set and read from it in the same job. You have to create a separate job for creating the Lookup File Set. If you try to drag an input link to the fileset, you'll get the following error:
You cannot create a Lookup File Set and read from it in the same job. You have to create a separate job for creating the Lookup File Set. If you try to drag an input link to the fileset, you'll get the following error:
The destination stage does not support input links when it has output links.